



The common methods are used to calculate the shortest path between two routers: Distance vector routing and link state routing.
1.Distance Vector Routing
In distance vector routing each router periodically shares its knowledge about the entire network with its neighbors.The three keys to understanding how this algorithms works are as follows:
-Knowledge about the whole network.Each router shares its knowledge about the entire network.It sends all of its collected knowledge about the network to its neighbors.At the outset,a router's knowledge of the network may be sparse.How much it knows.however, it unimportant: it sends whatever it has.
-Routing only to neighbors.Each router periodically sends its knowledge about the network only to those routers to which it has direct links.It sends whatever knowledge it has about the whole network through all of its ports.This information is received and kept by each neighboring router and used to update that router's own information about the network.
-Information sharing at regular intervals.For example. every 30 seconds,each router sends its information about the whole network to its neighbors.This sharing occurs whether or not the network has changed since the last time information was exchanged.
In distance vector routing,each router periodically shares its knowledge about the entire network with its neighbors.
Sharing Information
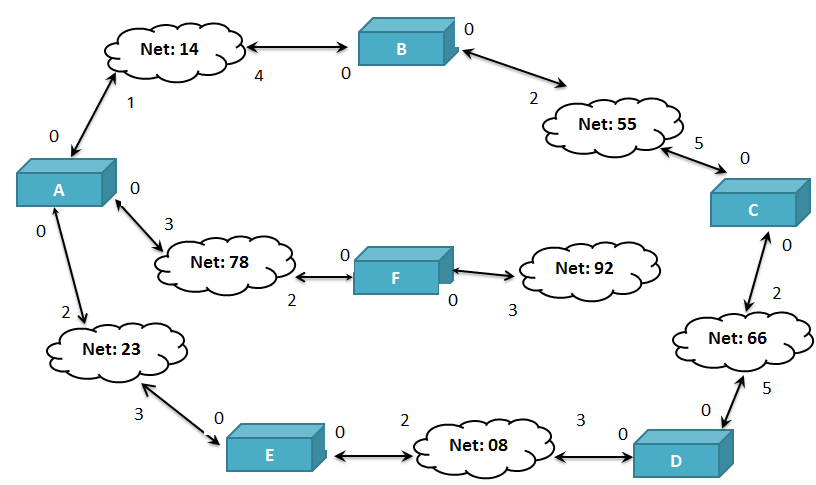
To understand how distance vector routing works,examine the internet shown is figure as below :

In this example, the ovals represent local area networks (LANs). The number inside each cloud is that LAN's network ID.These LANs can be of any type(Ethernet token ring.FDDI.etc.). The LANs are connected by routers(or gateways),represented by the boxes labeled A, B, C, D, E, and F.
Distance vector routing simplified the routing process by assuming a cost of 1 unit for every link.In this way,the efficiency of transmission is a function only of the number of links required to reach a destination.Distance vector routing,therefore is based not on cost but on hop count.
The boxes indicate the relationships of the routers in the above figure to their neighbors.As you can see,each router sends its information about the internetwork only to its immediate neighbors.How,then do non-neighboring routers learn about each other and share knowledge?The figure as below is shows the first step in the algorithm :

A router sends its knowledge to its neighbors.The neighbors add this knowledge to their own knowledge and send the whole table to their own neighbors.In this way,the first router gets its own information back plus new information about its neighbor's other neighbors.Each of these neighbors adds its knowledge and sends the updated table on to its own neighbors(to neighbors of neighbors of neighbors of the original router)and so on,eventually,every router knows about every other router in the network.
Routing Table
Now let's examine how each router gets its initial knowledge about the whole network(Internetwork) and how it uses shared information to update that knowledge.
Creating the Table
At start-up a router's knowledge of the inter-network is sparse.All it knows is that it is connected to some number of LANs(two or more)because a router is a station on each of those LANs.It also knows the ID of each station.In most systems, a station port ID and a network ID share the same prefix.So a router can discover to which networks it is connected by examining its own logical addresses(remember,a router has as many logical addresses as it has connected ports)this information is enough for it to construct its original routing table.
A routing table has columns for at least three types of information(some protocols require more): the network ID,the cost, and the ID of the next router.The network ID is the final destination of the packet.

The cost is the number of hops a packet must make to get there.And the next router is the router to which a packet must be delivered on its way to a particular destination.The table tells a router that it costs X to reach network Y via router Z.
The original routing tables for our sample inter-network are shown as figure as below :

At this point,the third column is empty because the only destination networks identified are those attached to the current router.No multiple-hop destinations and therefore no next routers have been identified.These basic tables are sent out to neighbors(as shown in the figure by arrows).
For example : A sends its routing table to routers B, F, and E.
B sends its routing table to routers C and A, and so on.Updating the Table
When A receives a routing table from B,it uses the information to update its own table.It says to itself:" B has sent me a table that shows how its packets can get to networks 55 and 14.I know that B is my neighbor,So my packets can reach B in one hop.So ,If I add one hop to all of the costs shown in B's table,the sum will be my cost for reaching those other networks." Therefore,A adjusts the information shown in B's table by adding one to each listed cost.It then combines this table with its own to create a new more comprehensive table.

This combined table may contain duplicate data for some network destinations.Router A therefore finds and purges any duplications and keeps whichever version shows the lowest cost.For example : router A can send a packet to network 14 in two ways.The first,which uses no next router,costs one hop.The seconds via router B,requires two hops(A to B,then B to 14).The first option has the lower cost, it is kept and the second entry is dropped.This selection process is the reason for the cost column,the cost serves as a weighting that allows the router to differentiate between various routes to the same destination.
Now,suppose that while A and B are exchanging tables ,router C receives a copy of D's routing table.C follows the same process as A and updates its table.Please see the figure as below :

One more the routing situation in our sample inter-working after A and C have updated their tables one as the figure as below:

If at this point,router F receives a copy of A's new table,it updates its own,Please see the below figure :

The inter-network after these first steps.Routers A, C, and F all have improved routing tables,Please see the figure as below:

The process continues until,after a certain number of table exchanges,each router's table shows the optimal path and hop count to each of the networks on the inter-network,for more details please see the figure as below:

If we examine the figure above we see that this simple procedure results in complete consistency among the routing tables,Imagine that router A receives a packet addressed to network 66.A looks at its table and sees that 66 is three hops away and that a packet destined for 66 first must be delivered to router E.Router A relays the packet to router E and forgets about it.A's duty is limited to delivering the packet to the next station on its route(one hop)In this case,router E takes it from there.
Router E now examines its own table and sees that to deliver a packet to network 66 requires two hops,the next of which is to router D.It therefore relays the packet to D and its responsibility ends.Router D receives the packet,looks at its own table,and finds that it is connected directly to network 66(one hop.no next router)network 66 delivers the packet to its final destination.
Link State Routing
The keys to understanding link state routing are different from those in distance vector routing.In link state routing,each router shares its knowledge of its neighborhood with every other router in the network.The following are true of link state routing:
In link state routing,each router shares its knowledge of its neighborhood with all routers in the inter-network.
1.Knowledge about the neighborhood, Instead of sending its entire routing table, a router sends information about its neighborhood only.
2.To all routers, Each router sends this information to every other router on the inter-network,not just to its neighbors.It does so by a process called flooding.Flooding means that a router sends its information to all of its neighbors(through all of its output ports) each neighbor sends the packet to all of its neighbors.And so on, Every router that receives the packet sends copies to all of its neighbors.Finally,every router(without exception) receives a copy of the same information.
3.Information staring at regular intervals, each router sends out information about the neighbors periodically.How ever,the interval in link state routing is normally much longer than the one in distance vector routing(Ex: ..30 minutes versus 30 seconds).
Information staring
Let's examine the link state routing process using the same inter-network we used for distance vector routing.
The first step in link state routing is information sharing.Each router sends its knowledge about its neighborhood to every other router in the inter-network.For more details pleas see the figure as below:
Concept of Link state routing

Packet Cost :
Both distance vector and link state routing are lowest cost algorithms.In distance vector routing,cost refers to hop count.In link state routing,cost is a weighted value based on a variety of factors such as security levels,traffic,or the state of the link.The cost from router A to network 14,therefore,might be different from the cost from A to 23.
In determining a route,the cost of a hop is applied to each packet as it leaves a router and enters a network.(Remember,cost is just a weighting and should not be confused with the transmission fees paid by the sender or receiver.) This cost is an outbound cost.meaning that it is applied when a packet leaves the router.Two factors govern how cost is applied to packets in determining a route:
- Cost is applied only by router and not by any other stations on a network.Remember,the link from one router to the next is a network,not a point-to-point cable.In many topologies(such as ring and bus),every station on the network examines the headers of every packet that passed.If cost was added by every station,instead of by routers alone,it would accumulate unpredictable(the number of stations in a network can change for a variety of reasons,many of them unpredictable).
-Cost is applied as a packet leaves the router rather than as it enters.Most networks are broadcast networks.When a packet is in the network,every station,including the router,can pick it up.Therefore,we cannot assign any cost to a packet when it goes from a network to a router.
The costs shown are arbitrary,in actual practice they would reflect attributes of each network,in figure below shows our sample internet as it appears to the link state routing algorithm.
Cost in link state routing

Link State Packet : When a router floods the network with information about its neighborhood,it is said to be advertising.The basis of this advertising is a short packet called a link state packet(LSP); .An LSP usually contains four fields,the ID of the advertiser,the ID of the destination network affected ,the cost,and the ID of the neighbor router.
Getting Information about Neighbors : A router gets its information about its neighbors by periodically sending them a short greeting packet.If the neighbor responds to the greeting as expected,It is assumed to be alive and functioning.If it does not a change is assumed to have occurred and the sending router then alerts the rest of the network in its next LSP.These greeting packets are small enough that they do not occupy network resources to any significant degree(unlike the routing tables used by distance vector routing).
Initialization : Imagine that all routers in our sample network come up at the same time.Each router sends a greeting packet to its neighbors to find out the state of each link,please see the figure as below :

It then prepares an LSP based on the results of these greetings and floods the network with it.The following figure shows this process for router A.
Flooding of A's LSP

The same steps are performed by every router in the network as each comes up, see in Flooding of B's LSP, router B's process.
Flooding of B's LSP

Link State Database : Every router receives every LSP and puts the information into a link state database.
Because every router receives the same LSPs, every router builds the same database. It stores this database on its disk, and uses it to calculate its routing table. If a router is added to or deleted from the system, the whole database must be shared to create fast updating.
In link state routing, every router has exactly the same link state database.
Please see the below figure :

The Dijkstra Algorithm
To calculate its routing table, each router applies an algorithm called the Dijkstra algorithm to its link state database. The Dijkstra algorithm calculates the shortest path between two points on the network using a graph made up of nodes and arcs. Nodes are of two types : Networks and routers.
Arcs are the connections between a router and a network (Router-to-Network and Network-to-Router). Cost is applied only to the arc from router to Network. The cost of the Arc from Network-to-Router is always Zero, Please the figure as below :
Shortest Path Tree : The Dijkstra algorithm follows four steps to discover what is called the shortest path tree (Routing table) for each router:
- The Algorithm begins to build the tree by identifying its root. The root of each router's tree is itself.The algorithm then attaches all nodes that can be reached from that root- in other words, all of the other neighbour nodes. Nodes and Arcs are temporary at this step.
- The Algorithm compares the tree's temporary arcs and identifies the Arc with the lowest cumulative cost. This Arc and the node that it connects to are now a permanent part of the shortest path tree.
The below figure shows the steps of the Dijkstra algorithm applied by node A of our sample internet. The cost number next to each node represents the cumulative cost from the root node, not the cost of the individual Arc. The second and third steps are repeated until four more nodes have become permanent.
Shortest Path calculation , Part 1









- The algorithm examines the database and identifies every node that can be reached from its chosen node.These nodes and their Arcs are added temporarily to the tree.
- The last two steps are repeated until every node in the network has become a permanent part of the tree. The only permanent Arcs are those that represent the shortest (lowest cost) route to every node.
The figure as below is shows the completion of the shortest path tree for router A :




Routing Table
Each Router now uses the shortest path tree to construct its routing table. Each Router uses the same algorithm and the same link state database to calculate its own shortest path tree and routing table : These are different for each Router.
In link state routing, the link state database is the same for all routers, but the shortest path trees and the routing tables are different for each Router.
The below figure shows the table developed by Router A :


0 comments:
Post a Comment
If there is any comments,Please leave a comment at here.